Music and Audio Research Lab: Machine Learning Internship

Project Summary
During 2021-2022, I returned as a research intern at the NYU Music and Audio Research Lab. My internship focused on studying the effect of lossy-based MP3 compression on the performance of machine learning recognition models.
In order to do so, I generated various Python scripts in order to separate, compress, and generate embeddings based on a pre-existing SONYC dataset. Afterwards, I used these embeddings to train various ML models at various compressions, and tested how well they could classify various sounds.
- Software: Python - KERAS, OpenL3, Spotify Pedalboard
- Date: November 2021 - September 2022
Project Breakdown
SONYC (Sounds of New York City) deploys acoustic recording devices to track noise pollution across NYC and often relies on a combination of expert, and crowdsourced volunteers in order to categorize and annotate the collected audio.
These annotations are incredibly time consuming and costly to produce, and so in response, MARL wants to implement machine learning audio recorders that could be able to identify and correctly classify the type of noise it is hearing. However, given that hours of audio are recorded at a time, storage quickly becomes an issue as they are currently recorded in WAV format which allows for lots of detail, but less recording time.
The compromise would be using compressed MP3 files in order to limit the storage size at the cost of losing audio quality. This is why my internship aimed to explore the possibilities of using compressed MP3 audio to train and test machine learning models to analyze how lossy-based compression impacts its performance.
Stratifying the Data
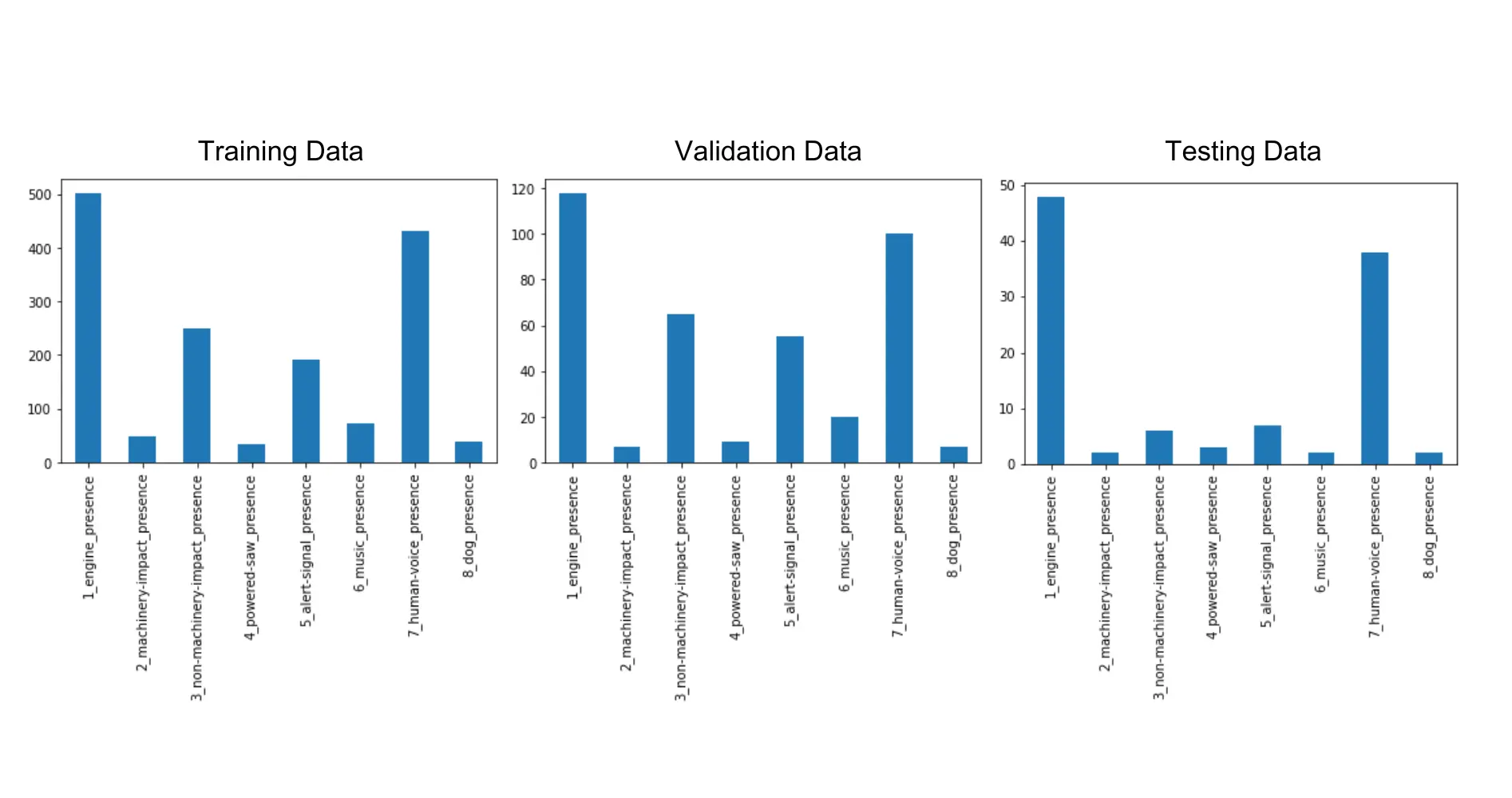
The project began with organizing our data in order to ensure that our machine model was being trained with a distribution that would reflect real world acoustic environments.
The SONYC dataset used was split into 8 different categories: engine’s, machinery-impact, non-machinery-impact, powered-saw, alert-signal, music, human-voice, and dog sounds. Each audio clip recorded was around 10 seconds long, and guaranteed at least one of these sounds present.
In order to ensure that the model could correctly identify each category without any overlap, I wrote a python script to filter out any audios that contained more than one type of sound, as well as focusing on annotations made by an expert to ensure there wouldn’t be conflicting data.
From here, I separated the remaining audio into both training and testing datasets with a similar breakdown between the two to ensure there were similar real-world distributions in both.
Sampled SNR & Generating Embeddings
Following this, I ran a script that would determine the highest SNR within each audio clip and then trim the clip to within a seconds range from the loudest moment. The reason for doing this was to cut down on the time it took to generate the embeddings, as well as ensuring that the model was properly trained to identify said sound.
Then, using OpenL3, I ran all of these trimmed audios through to create the embeddings and exported them as a CSV file to be read by the model later on.
Creating Compressed Datasets
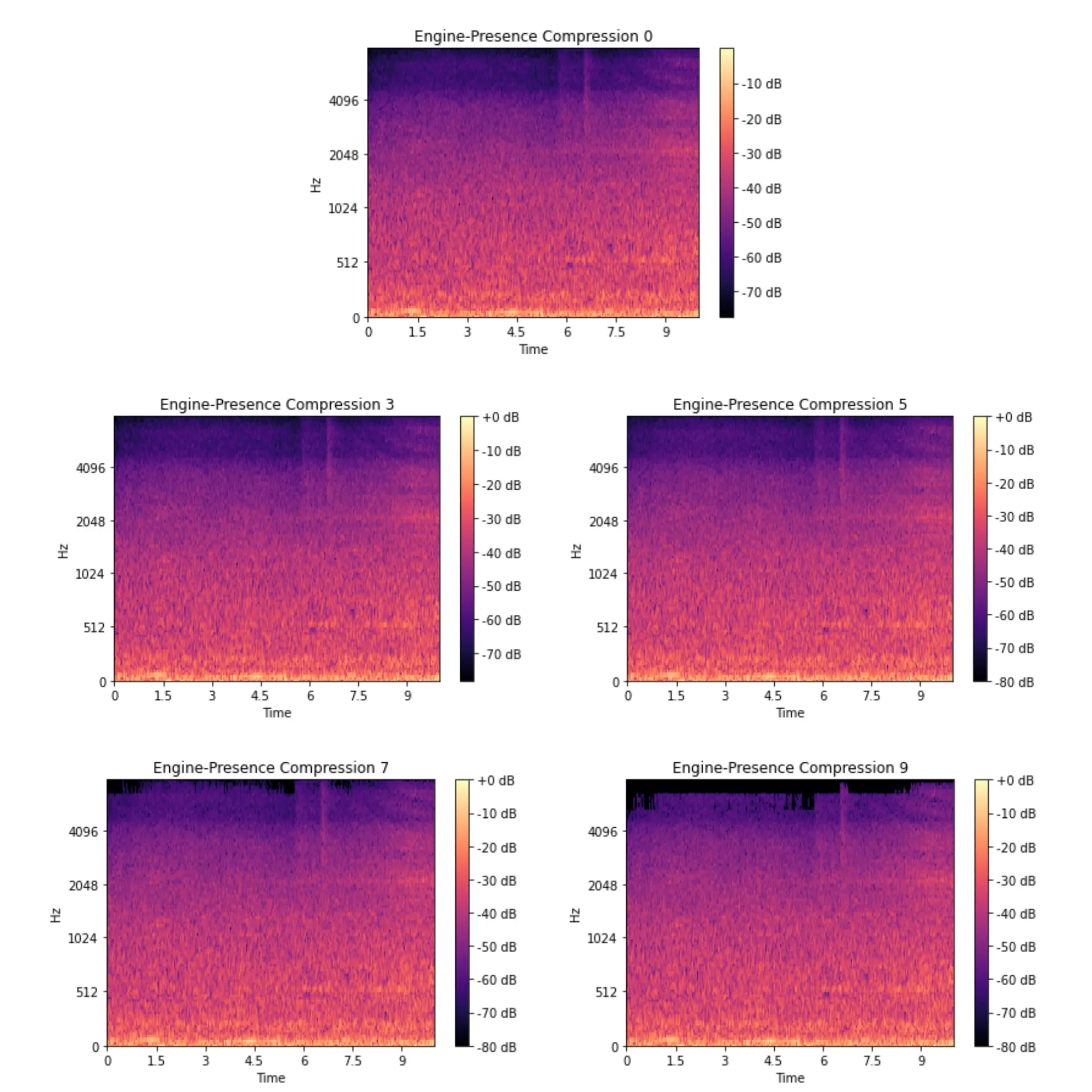
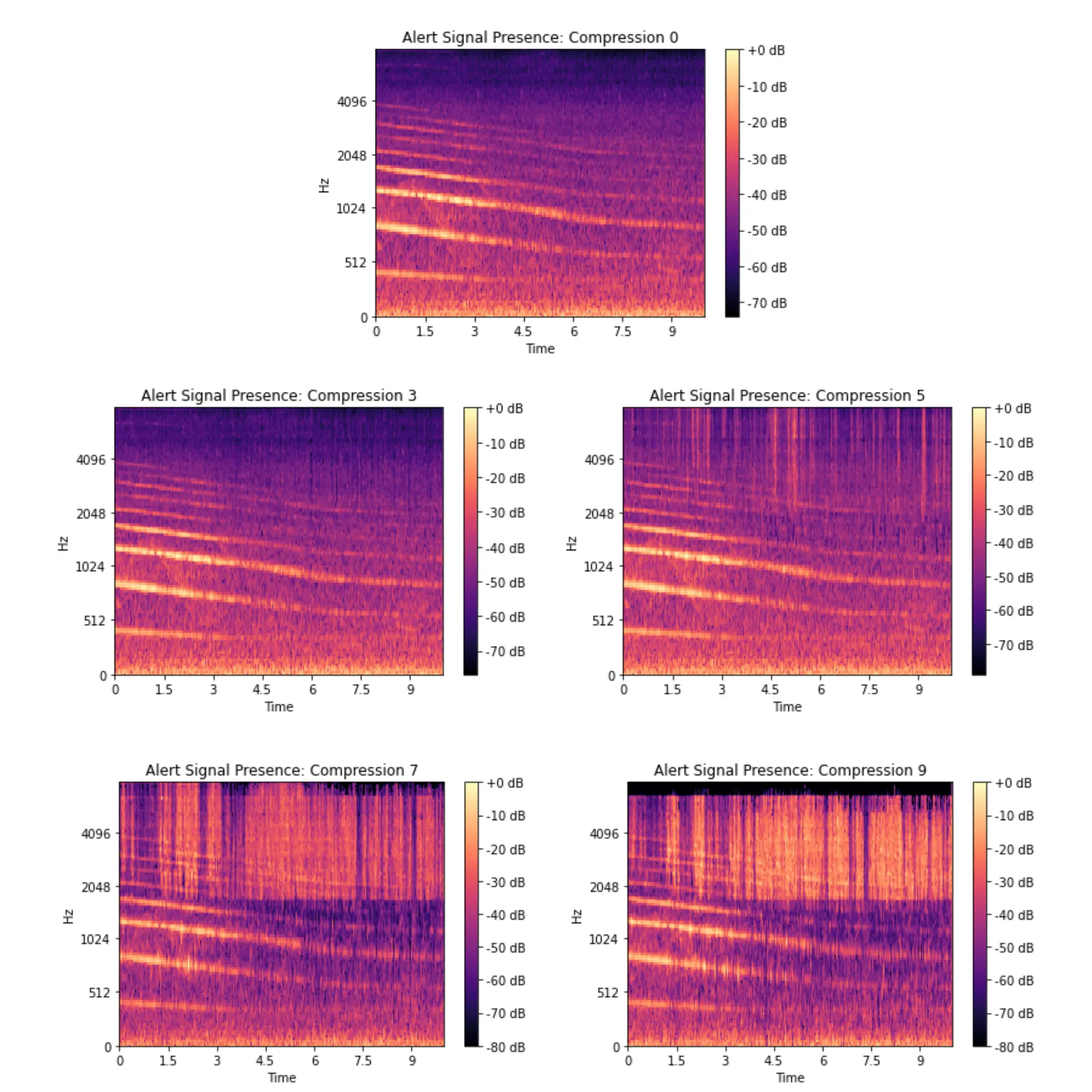
Using Spotify’s Pedalboard library, I wrote a script to then create compressed MP3 versions of the original filtered dataset. Pedalboard uses a lossy based algorithm to compress audio on various levels between 1-9 (9 being the highest level of compression).
With this, I generated four compressed datasets at levels 3, 5 , 7 and 9 and separated them into testing, training, and validation subsets based on the distribution of the original dataset. To get a visual representation of the way certain classes changed after being compressed, I created spectograms to help identify a potential breaking point for the model.
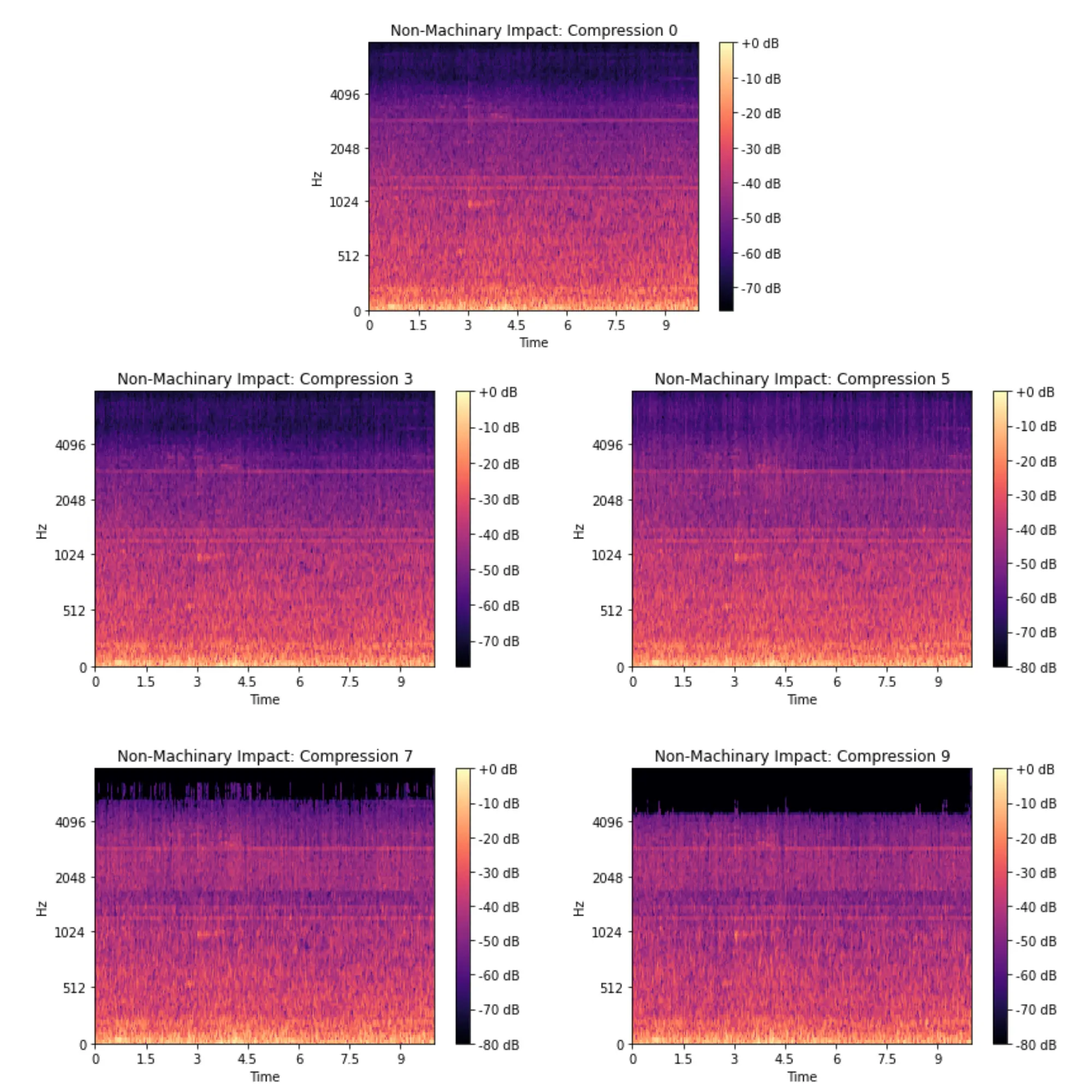
Running the Model
Using KERAS, I trained a machine learning model using the training data of the zero compression dataset, and would run it against the embeddings of the testing dataset at various compression levels in order to see the cutoff point for the model's accuracy.
Following this, I then trained two separate model’s using the level 3 and level 5 compressed training data and tested it against the various compression levels as well, giving us a total of three separate models. When tested on their respective compressions (ex: trained with level 0/tested with level 0, trained with level 3/tested with level 3, etc), the models averaged as follows:
Original Compression- Train Accuracy: 72.91% | Val Accuracy: 59.87%
Compression Lvl 3- Train Accuracy: 67.49% | Val Accuracy: 56.58%
Compression Lvl5- Train Accuracy: 70.28% | Val Accuracy: 51.32%
Final Results
After running all of the models, I measured their performance by creating a confusion matrix with the true positives, false positives, false negatives, precision, recall and the F1 accuracy values.
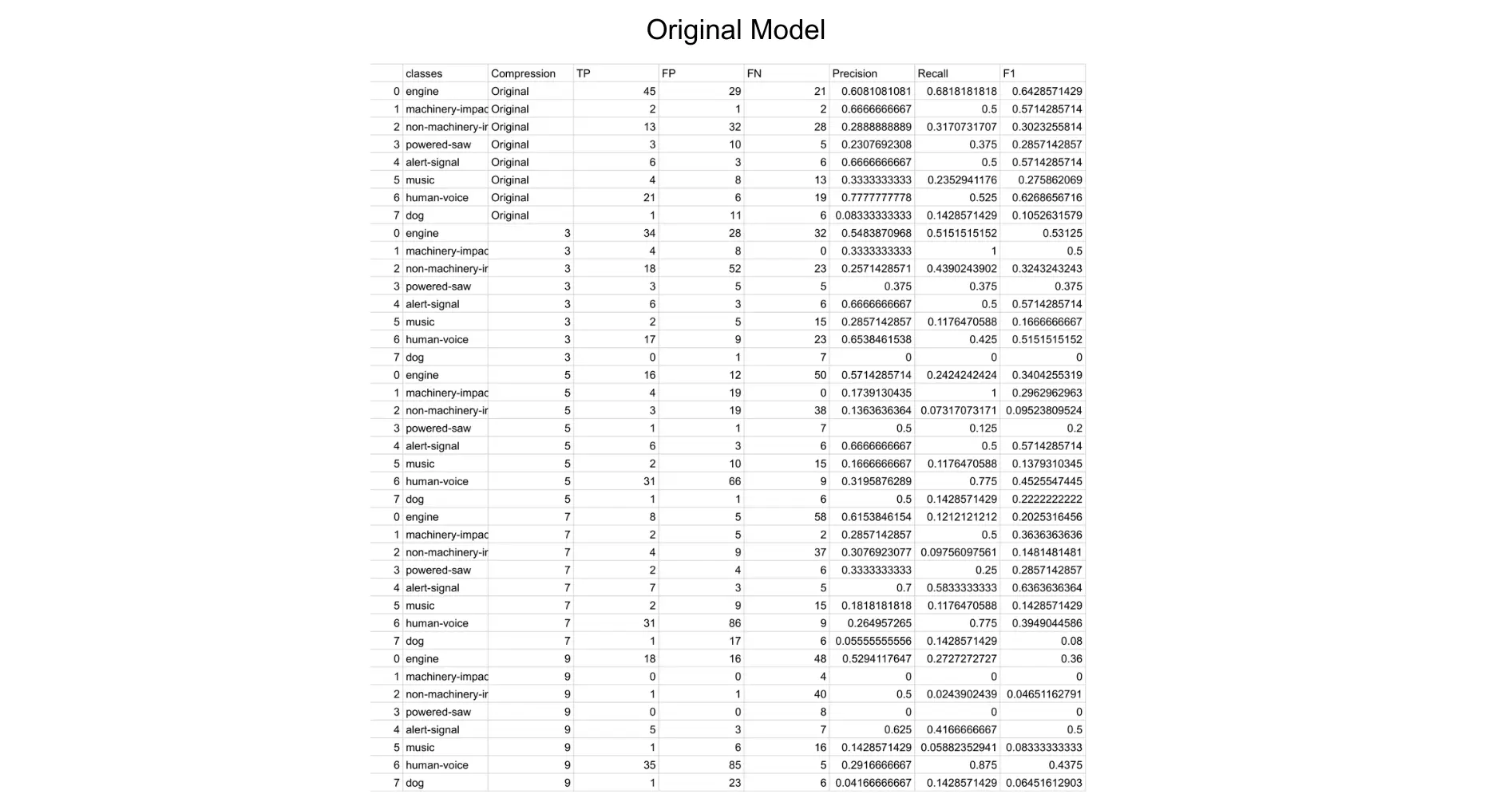
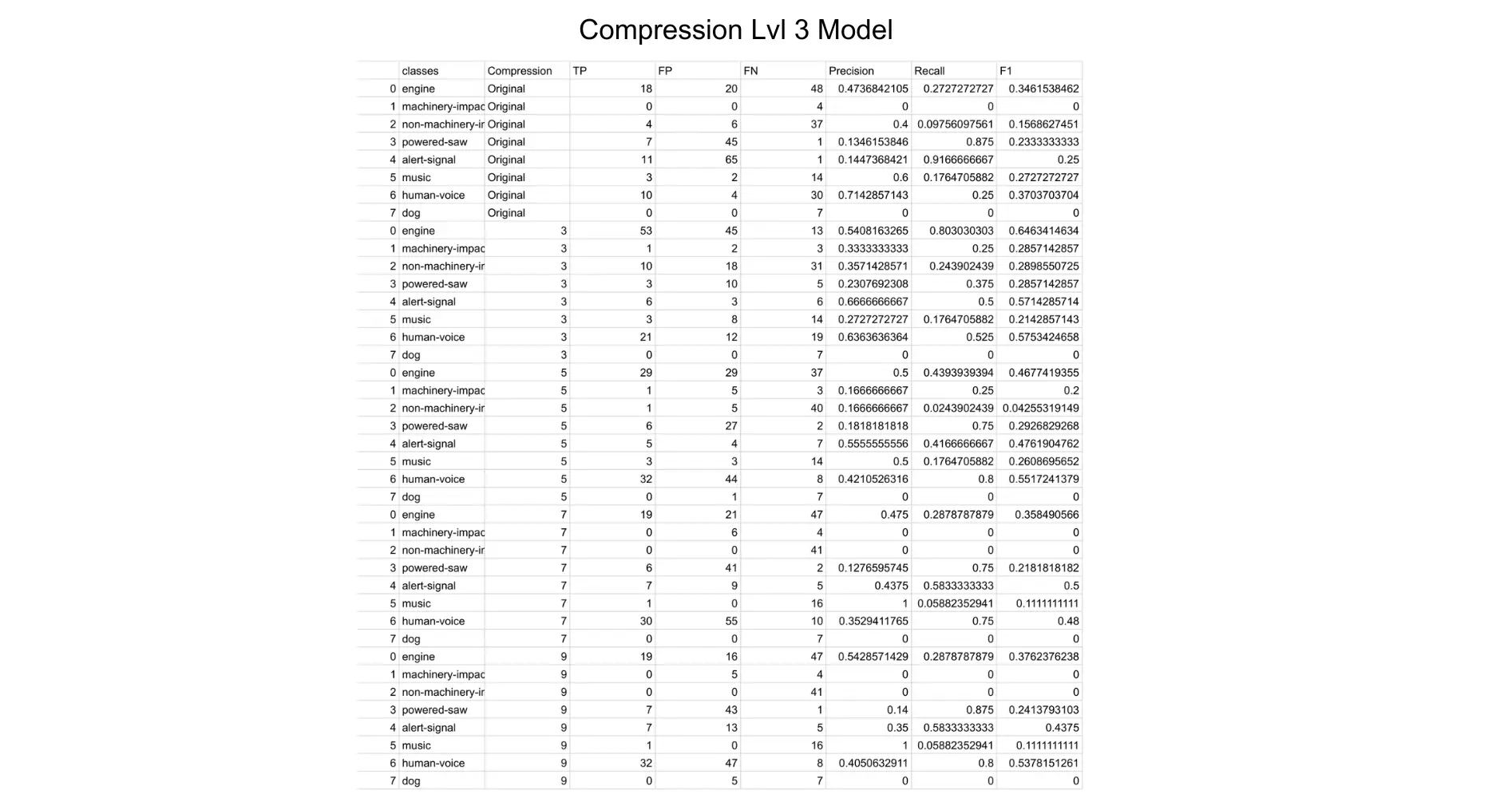
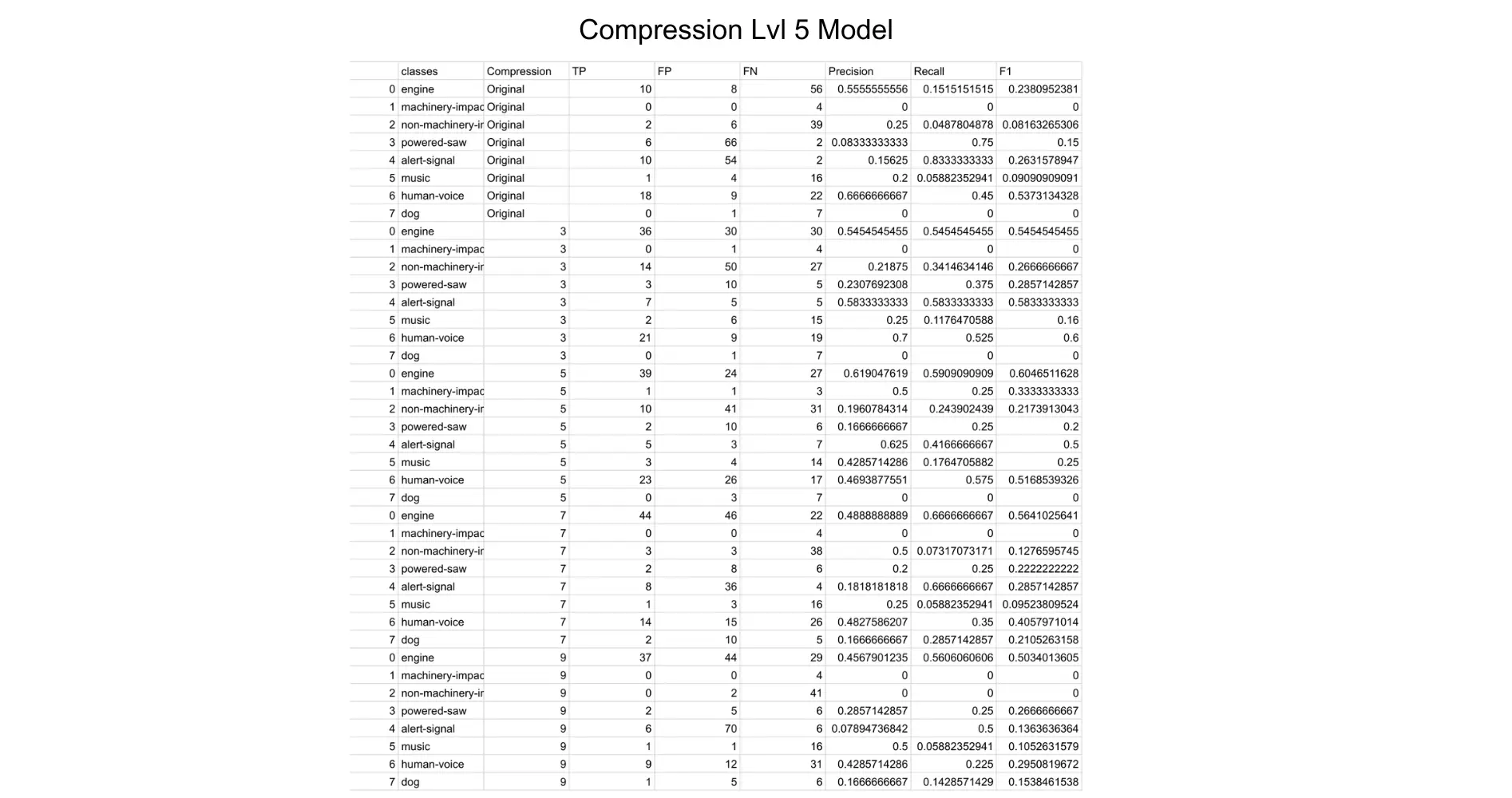
The F1 values were then graphed and we could compare how each model performed in certain categories.
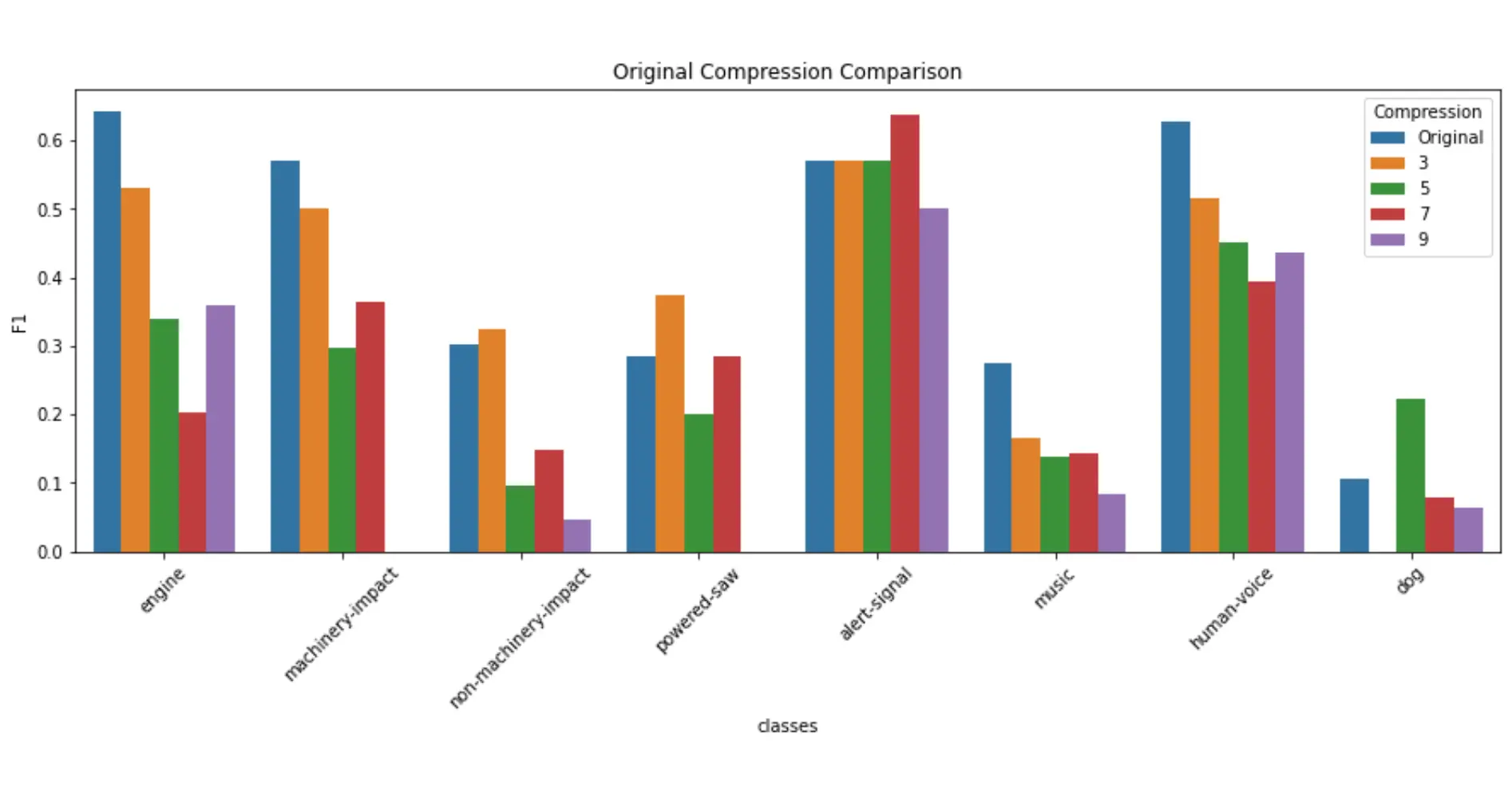
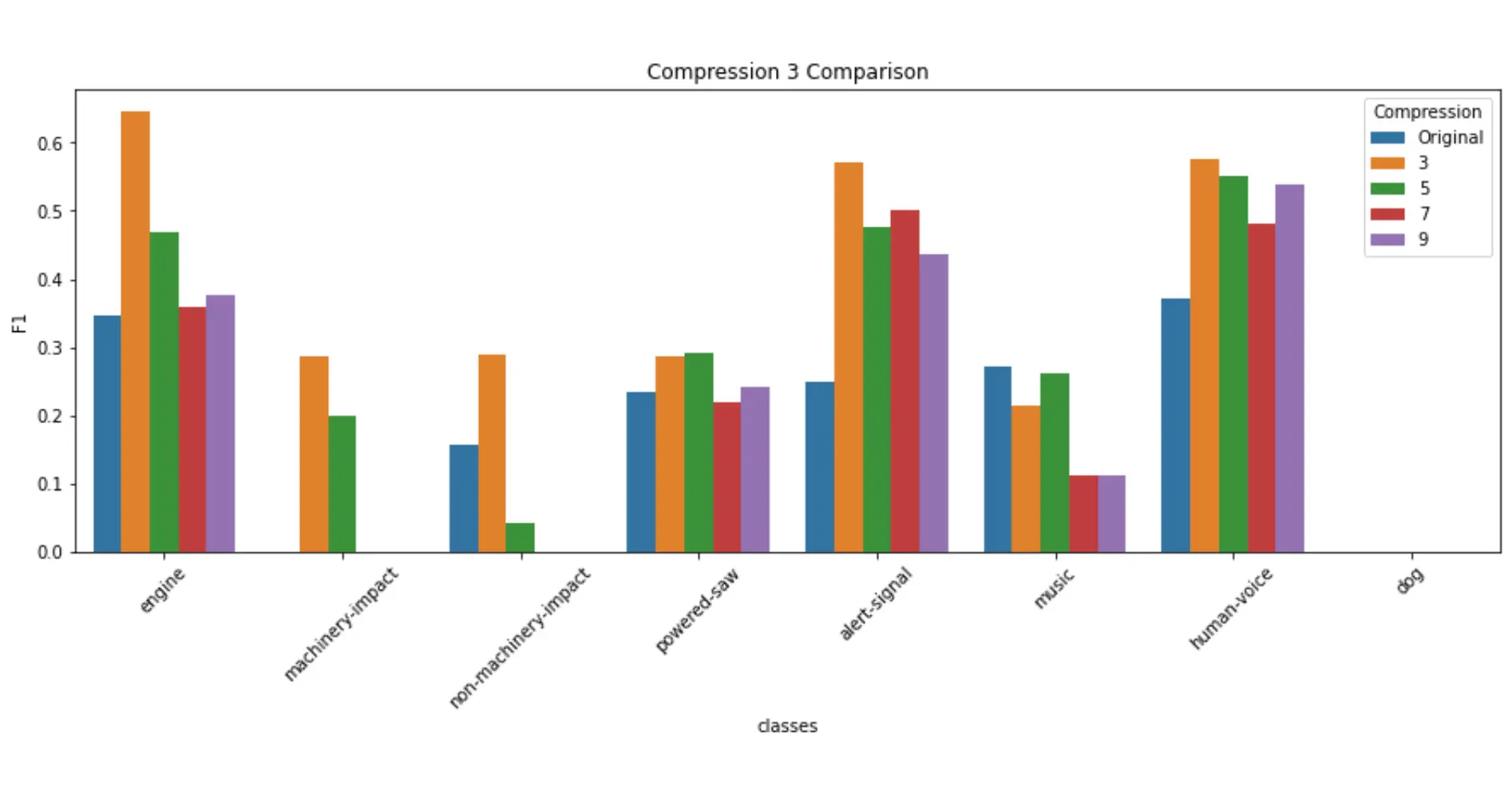
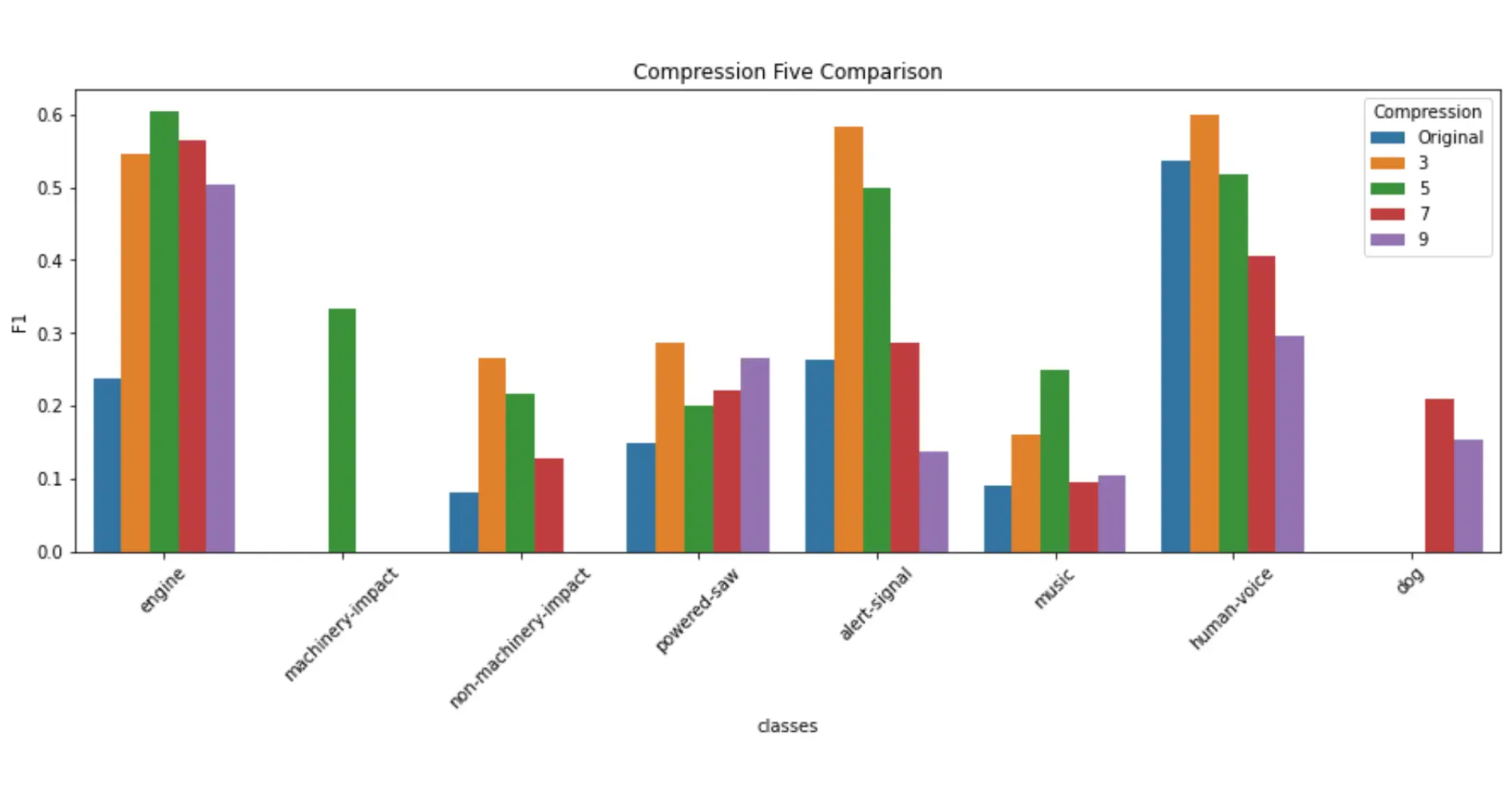
Unsurprisingly, the original trained dataset performed best, and would usually lower in accuracy as the compression levels raised. However, there were certain categories that would actually perform better when compressed, leading us to wonder whether this is due to the type of sound/duration, or a disbalance in testing data.
Reflection
This experience was one that taught me a great amount about machine learning while building off of my previous experience working within the field of audio research.
Looking at further avenues of exploration, its worth mentioning that some of the results could have been impacted by the step in which we sample the highest SNR in each audio clip. The assumption being that, the loudest SNR would mean that is the most likey point to contain the classified sound. However, this is not a guarantee and it could result in the model incorrectly learning what certain categories sound like.